「超巨大高性能モデルGPT-3の到達点とその限界. この記事では、超巨大言語モデルGPT-3の技術的な解説、GPT-3達成したことと… | by akira | Jul, 2020 | Medium」
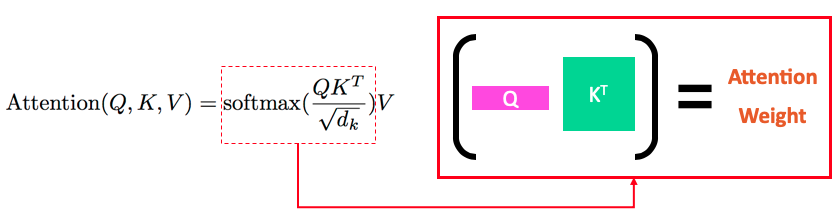
![まず、GPT-3の前身となったGPT-2に入る前に、その中に使われているTransformer Encoderの解説をします。Transformer[2]は“Attention Is All You Need”という論文で提案されたモデルで、LSTM・CNNを愛用していた人たちに対する挑発的なタイトルでも話題になりました。 Transformerで使われる(dot-product)…](/assets/img/1595578760.jpg)
まず、GPT-3の前身となったGPT-2に入る前に、その中に使われているTransformer Encoderの解説をします
Webページ
コンテンツ文字数:11,414 文字
見出し数(H2/H3タグ):0 個
閲覧数:263 件
2020-07-24 17:19:20
オリジナルページを開く
リンク
画像一覧






































































タグ一覧
※読み込みに時間がかかることがあります
ⓘ